1. The different types of… Types in Scala
这篇博客是我在 2013 年参加了数个 JavaOne 会议,多次与人们讨论 Scala 中的类型之后写下的。经过这些讨论,我发现不同的人学习 Scala 时都会重复询问许多类似的问题。 我认为这是因为我们没有一个完整记录 Scala 类型技巧的列表,所以我决定写这样的一个列表 - 用现实生活的例子解释为什么我们需要这些类型。
2. WORK IN PROGRESS
虽然我在这篇博文已经花了不少时间,但是其中还有很多未完成。 比如 Higher Kinds 部分需要重写,Self Type 部分添加更多的细节等等。请查看 TODO。
如果你想帮忙的话,请不要犹豫!我欢迎任何形式的 pull request 或者建议(呃,我更喜欢 pull request;-)
另外,如果你看到某个小节标记着 "✗" ,这意味着这部分需要重写或者还没有完成。
3. Type Ascription
Scala 有类型推断,这意味我们不需要每次都在源代码中声明变量的类型,可以直接使用 val 或者 def 。
这种显式声明变量类型的方式称为 Type Ascription(有时也称为 "Type Annotation",
但是这样的名字很容易引起误解,所以没有在 Scala 规范中使用)。
trait Thing
def getThing = new Thing { }
// 没有 Type Ascription,变量类型被推导为 `Thing`
val inferred = getThing
// 有 Type Ascription
val thing: Thing = getThing
在上述情况下,我们可以省略 Type Ascription。不过你可能会决定总是描述公有方法(public methods)的返回类型(这是一个好主意!),使得代码更加自我文档化。
当你犹豫的时候,可以参考下面的提示问题来决定是否使用 Type Ascription:
-
是一个参数吗?如果是的话,那么你必须加上。
-
是公有方法的返回值吗?如果是的话,那么需要加上以便于代码自我文档化和控制返回类型。
-
是递归或者重载方法的返回值吗?如果是的话,那么你必须加上。
-
你是否需要返回一个比推导器推导的更通用的类型?如果是的话,那么需要 Type Ascription,不然你就会向客户端暴露代码实现细节
-
否则的话…不要加上 Type Ascription
-
相关提示:加上 Type Ascription 可以加快编译速度,并且能看到方法的返回类型也是很好的
所以我们在变量名字后加上 Type Ascription。说了这么多,让我们进入下一个话题,其中这些类型会变得越来越有趣。
4. Unified Type System - Any, AnyRef, AnyVal
我们之所以称 Scala 的类型系统是"统一"的,是因为它有一个最顶层类型 Any。
这不同于 Java,Java 存在原始类型的"特殊情况"(int, long, float, double, byte, char, short, boolean),这些类型不继承 Java 的"近似顶层类型" - java.lang.Object。
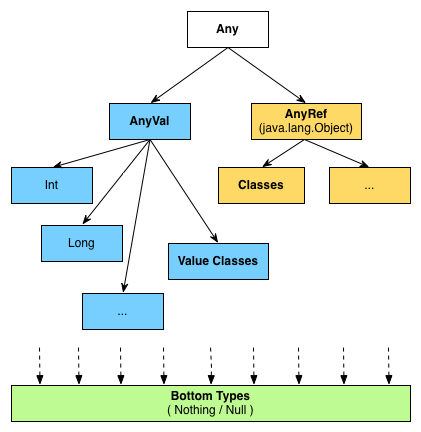
Scala 通过引入 Any 使得所有类型都有一个通用顶层类型。Any 是 AnyRef 和 AnyVal 的父类。
AnyRef 是 Java(以及 JVM)的"对象世界(object world)",对应 java.lang.Object,是所有对象的父类。
另一方面,AnyVal 对应 Java 的"值世界(value world)",比如 int 和其它 JVM 原始类型。
得益于这样的层次结构,我们可以定义接受 Any 的方法 - 兼容 scala.Int 和 java.lang.String:
class Person
val allThings = ArrayBuffer[Any]()
val myInt = 42 // Int, 运行时保持 JVM 原始类型 `int`
allThings += myInt // Int(继承 AnyVal)
// 需要装箱(!) -> 在集合中变成 java.lang.Integer(!)
allThings += new Person() // Person(继承 AnyRef),没有特别的地方
类型系统能透明地处理值和对象的集成或者共同存在,但一旦我们在 JVM 级别进入 ArrayBuffer[Any],我们的 Int 实例会被打包成对象。
让我们使用 Scala REPL 和它的 :javap 命令(该命令可以展示编译器生成的字节码)来研究上面的例子:
35: invokevirtual #47 // Method myInt:()I
38: invokestatic #53 // Method scala/runtime/BoxesRunTime.boxToInteger:(I)Ljava/lang/Integer;
41: invokevirtual #57 // Method scala/collection/mutable/ArrayBuffer.$plus$eq:(Ljava/lang/Object;)Lscala/collection/mutable/ArrayBuffer;你能注意到 myInt 仍是一个 int primitive 类型的值(从 myInt:() I invokevirtual 调用后的 I 可以看出)。
然后,在将其加入 ArrayBuffer 之前,scalac 插入了一个 BoxesRunTime.boxToInteger:(I)Ljava/lang/Integer 的调用(给没有经常阅读字节码读者的一个小提示,scalac 实际调用的是 public Integer boxToInteger(i: int))。
通过一个聪明的编译器,将所有变量都作为这个公共类型结构中的一个对象,这么做,至少在 Scala 源代码层面,我们可以远离"但是原始类型是不同的"窘况 - 编译器会帮我们处理这种情况。
在 JVM 层面,当然区别还是存在的,scalac 会尽可能的使用原始类型,因为原始类型的操作更快,并且占用更少的内存(对象显然大于原始类型)。
另一方面,我们可以限制一个方法只能接受"轻量级"值类型:
def check(in: AnyVal) = ()
check(42) // Int -> AnyVal
check(13.37) // Double -> AnyVal
check(new Object) // -> AnyRef = 编译失败
在上面的例子中,我们使用了一个 TypeClass Checker[T] 和一个类型绑定,这将在下面讨论。
总体思路是,这个方法只接受 Value Classes,可以是 Int 或者自定义的 Value 类型。
虽然这样的用法不常见,但是它很好地展示了类型系统是如何拥抱 Java 原始类型,并将它们引入到"真实"的类型系统,
而不是像 Java 那样区分出引用类型和值类型。
5. The Bottom Types - Nothing and Null
Scala 中,每个变量都有"某种"类型…但是你是否想过在某些"奇怪"的情况下,类型推导器(type inferencer)是如何能继续工作的, 比如抛出了异常。让我们来看看下面这个 "if/else throw" 例子:
val thing: Int =
if (test)
42 // : Int
else
throw new Exception("Whoops!") // : Nothing
正如你在注释中看到,if 语句块的类型是 Int(容易推导),else 语句块的类型是 Nothing(有趣)。 推导器推导出 thing 的类型只能是 Int,这是因为 Nothing 的 Bottom Type 属性。
一个关于 bottom types 如何工作的直观理解是:"Nothing extends everything."
|
类型推导器总会寻找 if/else 语句两个分支的"公共类型",所以如果一个分支有一个继承了所有类型的类型, 那么另一个分支的类型就会自动成为 if/else 表达式的类型。
类型可视化:
[Int] -> ... -> AnyVal -> Any
Nothing -> [Int] -> ... -> AnyVal -> Any
这样的推导方式也适用于 Scala 的第二个 Bottom Type - Null。
val thing: String =
if (test)
"Yay!" // : String
else
null // : Null
正如预料中那样 thing 的类型是, String。Null 遵循与 Nothing 几乎一样的规则。
我会用这个例子来谈谈类型推导,以及 AnyVals 和 AnyRefs 之间的区别。
类型可视化:
[String] -> AnyRef -> Any
Null -> [String] -> AnyRef -> Any
推导类型:String让我们思考下 Int 和其他不能包含 null 的原始类型。为了研究这种情况,让我们进入 REPL 并使用 :type 命令(这条命令可以得到表达式的类型):
scala> :type if (false) 23 else null
Any这与上面例子中一个分支返回 String 对象的情况不同。
让我们来看看这里的详细类型,相比 Nothing 继承 everything,Null 继承的类型会少一点。
让我们再次使用 :type 看看 Int 的继承关系:
scala> :type -v 12
// 类型签名
Int
// 内部类型结构
TypeRef(TypeSymbol(final abstract class Int extends AnyVal))在这里,可见选项(-v)输出了更多的信息,现在我们知道 Int 是一个 AnyVal - 是一个代表值类的特殊类 - 不能接受 Null。
如果我们查看 AnyVal 实现,我们会发现:
abstract class AnyVal extends Any with NotNull
(注意,上面的代码是 Scala 2.10.x 及之前的 AnyVal 实现;从 2.11.x 之后,NotNull 就被移除了)
我之所以在这里提到这个,是因为 AnyVal 的核心功能被很好的用类型表达出来。注意 NotNull 特质!
回到刚才的主题,为什么我们的 if 语句,其中一个分支的类型是 AnyVal 然后另一个分支的类型是 Null 的公共类型是 Any 而不是其他类型。
一句简洁的解释就是: Null 继承所有 AnyRefs 而 Nothing 继承 anything。
因为 AnyVals(比如 numbers)与 AnyRefs 不在同一颗继承树上,那么一个 number 和一个 null 值的公共类型只能是 Any - 这就是上述情况的解释。
类型可视化:
Int -> NotNull -> AnyVal -> [Any]
Null -> AnyRef -> [Any]
推导类型:Any
6. Type of an object
Scala 的 object 是基于类实现的(这是很显然的 - 因为类是 JVM 的基本构建模块),
但是你会注意到我们无法像获得类的类型那样获得一个 object 的类型。
令人惊讶的是,我经常被问到如何传递一个 object 给一个方法的问题。
如果仅使用 obj: ExampleObj 是不能通过编译的,这是因为 ExampleObject 已经指向 object 实例了,在这种情况下应该使用一个叫做 type 的方法。
下面的例子展示了如何使用 type 方法:
object ExampleObj
def takeAnObject(obj: ExampleObj.type) = {}
takeAnObject(ExampleObj)
7. Type Variance in Scala
一般来说,variance 可被解释为类型之间的"类型兼容性",形成一个 extends 关系。
你需要处理这种问题的最常见情况是使用容器或者函数(你会惊讶的发现这种情况是非常频繁的!)。
Scala 与 Java 的一个主要区别是,容器类型默认并不是协变的(not-variant by default)。
这意味着如果你定义了一个容器 Box[A],然后使用 Fruit 代替类型参数 A,那么你不能插入一个 Apple 到容器内(Apple 确实是水果,IS-A 关系)。
在 Scala 中,Variance 是通过在类型参数前加上 + 或者 - 符号定义的
| 名字 | 描述 | Scala 语法 |
|---|---|---|
Invariant |
C[T'] and C[T] 不相关 |
C[T] |
Covariant |
C[T'] 是 C[T] 的子类 |
C[+T] |
Contravariant |
C[T] 是 C[T'] 的子类 |
C[-T] |
上面的表格以抽象的形式展现了我们需要关心的所有 variance。 你可能想知道在哪里你需要关心这些呢。事实上,每次你使用集合时你都面临这样的问题:"它是协变的吗?"。
| 大多数不可变(immutable) 都是协变的(covariant),大多数可变(mutable)集合都是不变的(invariant). |
在 Scala 中至少有两个关于 variance 很好并且非常直观的例子。第一个例子是"任何集合",我们使用 List[+A] 作为集合的代表;
第二个例子出现在函数的使用中,我们将不会在这里介绍。
当讨论 Scala 的 List 时,我们通常指的是 scala.collection.immutable.List[+A],既是不可变又是协变的。
让我们看看 variance 与构建一个包含不同类型的列表有何关联。
class Fruit
case class Apple() extends Fruit
case class Orange() extends Fruit
val l1: List[Apple] = Apple() :: Nil
val l2: List[Fruit] = Orange() :: l1
// 并且我们可以很安全的向前添加任何元素
// 这是因为我们在构建一个新的 list - 而不是修改原来的实例
val l3: List[AnyRef] = "" :: l2
值得一提的是,尽管让不可变集合具有协变特性是安全的,但是对于可变集合就不成立。
一个经典的例子是不可变的 Array[T]。让我们来看看这里不变性对我们来说意味着什么,以及它是如何从错误中拯救我们的:
// 不能通过编译
val a: Array[Any] = Array[Int](1, 2, 3)
因为数组的不可变性,上述赋值是不能通过编译的。
假设这样的赋值是合法的,那么我们就可以这样写出这样的代码:a(0) = "" // ArrayStoreException!,会导致令人畏惧的 ArrayStoreException。
我说 Scala 中"大部分"不可变集合都是协变的。如果你好奇的话,一个反例是 Set[A],虽然它是不可变集合,但是它是不变的。
|
7.1. Traits, as in "interfaces with implementation"
首先,让我们看看我们用特质(Trait)能做到的最简单的事情: 我们是如何处理一个混入了多个特质的类型,就好像它实现了这些"带有实现的接口" - 如果你来自 Java 世界,你有可能会试图这样称呼特质。
class Base { def b = "" }
trait Cool { def c = "" }
trait Awesome { def a ="" }
class BA extends Base with Awesome
class BC extends Base with Cool
// 正如你所预料的,你可以将这些实例转换成它们混入的任意特质类型
val ba: BA = new BA
val bc: Base with Cool = new BC
val b1: Base = ba
val b2: Base = bc
ba.a
bc.c
b1.b
到目前为止,这对你来说应该是相当直接的。现在让我们深入"菱形问题"的世界,C++ 开发人员应该熟悉这一点。 基本上,"菱形问题"就是存在多重继承的情况下,我们无法确定哪个是直接父类。 如果我们将特质组合看成是多重继承的用法,那么下面的图片就演示了这个问题:
7.2. Type Linearization vs. The Diamond Problem
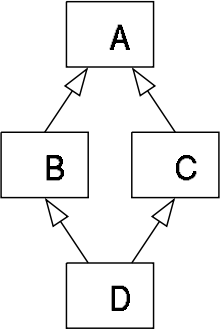
为了产生"菱形问题",我们只要在 B 或者/并且 C 中有一个覆盖实现。
这样的话,当调用 D 的方法时,我们就引入了歧义性。在 D 中,我们调用的是继承来自 C 还是来自 B 的方法?
在 Scala 中,只有一个覆盖方法时是非常简单的 - 覆盖方法胜利。但是,让我们考虑更复杂的案例:
-
类
A定义了一个方法common返回a, -
特质
B覆盖了common返回b, -
特质
C覆盖了common返回c, -
类
D继承了BandC, -
类
D继承了哪个版本的common方法呢?是来自C的覆盖实现,还是来自B的呢?
这种模糊性是每个类似多继承机制的痛点。Scala 通过所谓的 Type Linearization 解决这个问题。
换句话说,给定一个菱形的类结构,我们总是(确定性地)可以决定在 D 的内部调用 common 时哪个覆盖方法会被调用。
让我们用代码实现,然后再讨论线性化:
trait A { def common = "A" }
trait B extends A { override def common = "B" }
trait C extends A { override def common = "C" }
class D1 extends B with C
class D2 extends C with B
检查上述类型,我们获得下面的运行时行为:
(new D1).common == "C"
(new D2).common == "B"
之所以会出现这样的结果,是因为在这里 Scala 为我们应用了 type linearization。算法流程如下:
-
从头构建一个类型的列表,列表的第一个元素是我们正在线性化的类型
-
递归地扩展每个父类,并把这些类型都放到这个列表中(列表应该是平坦而不是嵌套的)
-
从结果列表中删除重复项,从列表左边开始扫描,去除已经"看到过"的类型
-
完成
让我们对上面的菱形例子应用这个算法,验证为什么 D1 extends B with C(和 D2 extends C with B)会返回这样的结果:
// 从 D1 开始
B with C with <D1>
// 对每一个类型,扩展它直到到达 Any
(Any with AnyRef with A with B) with (Any with AnyRef with A with C) with <D1>
// 从左到右,通过删除"已经看到"的类型,去除冗余
(Any with AnyRef with A with B) with ( C) with <D1>
// 书写最后的结果类型
Any with AnyRef with A with B with C with <D1>
现在调用 common 方法时,我们可以很简单的决定调用的是哪个版本:
我们只需要查看线性化类型,并尝试从右向左解析方法调用。
在 D1 的例子中,处于"最右边"并且能提供的 common 实现的是特质 C,
所以它覆盖了 B 提供的 common 实现。那么在 D1 内部调用 common 的结果就是 "c"。
你可以通过对类 D2 运行这个算法来加深理解 - B 应该线性化在 C 的右边,所以当你运行代码时会返回一个 "b"。
对于这样简单的线性化例子,我们可以仅考虑"最右边的赢",这样的想法非常简单易于理解,但是没有给出线性化算法的全貌。
值得一提的是,使用这个技巧,我们现在还可以回答"谁是我的 super?。对于任意的类,如果你想检查谁是你的父类,只需要检查线性化类型的左边。比如在我们的例子(D1)中,C 的父类是 B。
8. Refined Types (refinements)
Refinements 可以很容易的解释为"继承而无需命名子类"("subclassing without naming the subclass")。所以在代码中,refinements 看起来像:
class Entity
trait Persister {
def doPersist(e: Entity) = {
e.persistForReal()
}
}
// 我们的 refined 实例(和类型):
val refinedMockPersister = new Persister {
override def doPersist(e: Entity) = ()
}
9. Package Object
Package object 在 Scala 2.8 中加入,尽管它没有很好的扩展类型系统, 但是提供了一个非常有用的模式,允许我们"一次性导入一堆东西(importing a bunch of stuff together)",同时还是编译器寻找隐式转换的地方。 这里,我们的讨论将局限于它的第一个用法,即将数据聚合在一起:
声明一个 package object 很简单,只需要使用关键字 package 和 object,例如:
// src/main/scala/com/garden/apples/package.scala
package com.garden
package object apples extends RedApples with GreenApples {
val redApples = List(red1, red2)
val greenApples = List(green1, green2)
}
trait RedApples {
val red1, red2 = "red"
}
trait GreenApples {
val green1, green2 = "green"
}
通常人们会将 package object 放在一个名为 package.scala 的文件中,
再将该文件又放在这些对象所属的包下,例如上面的源文件路径和 package。
使用时,你会获得极大的好处, 这是因为当你导入这个 "package" 时, 你会导入定义在该 package 中的任何状态:
import com.garden.apples._
redApples foreach println
10. Type Alias
Type alias 实际上并不是一种类型,而是一个能用来提高我们代码可读性的技巧:
type User = String
type Age = Int
val data: Map[User, Age] = Map.empty
使用这个技巧,现在 Map 的定义一下变得"合理"了。
如果我们只是使用了一个 String => Int 类型的 map,那么我们会降低代码的可读性。
在这里,我们可以继续使用原始类型(也许我们需要原始类型的性能等),但是使用 Type Alias 命名它们,便于以后的读者理解这个类。
注意,当你为一个类创建别名时,不会将伴生对象关联在一起。例如,
假设你定义了一个 case class Person(name: String) 和一个别名类型 User = Person。
调用 User("John") 会导致错误,因为 Person("John") 会隐式调用 Person 伴生对象的 apply 方法,
但是伴生对象在这种情况下没有被定义别名,所以 User("John") 就报错。
|
11. Abstract Type Member
让我们进一步深入使用 Type Aliases,这样的用法称为 Abstract Type Members。
有了 Abstract Type Members,我们可以做到"定义一个抽象类型,并希望其他人告诉我具体类型 - 我们可以用 MyType 来引用这个类型"。
Abstract Type Members 最基础的功能是允许我们无需使用 class Clazz[A, B] 构建泛型类(模板),
我们可以在类中命名 abstract type member(s),例如:
trait SimplestContainer {
type A // Abstract Type Member
def value: A
}
对于熟悉 Java 的人来说,上面的语法看起来与 Container<A> 类似,
但我们会在 Path Dependent Types 和下面的例子中看到 Abstract Type Members 功能更强大。
需要注意的是尽管 type A 的注释中包含 "abstract",但是它与抽象字段不同 - 所以即使我们不"实现"类型成员 A,也可以创建一个 SimplestContainer 实例:
new SimplestContainer // 合法,但是 A 是 "anything"
你可能想知道 A 是什么类型,考虑到我们没有提供任何关于它的信息。事实上,type A 是 type A >: Nothing <: Any 的简写,意味着 A 可以是"任意类型(anything)"。
object IntContainer extends SimplestContainer {
type A = Int
def value = 42
}
因为我们使用 Type Alias 提供了一个抽象类型,现在我们可以实现一个返回 Int 的方法。
当我们对 Abstract Type Members 应用类型约束时,事情变得更有趣了。
比如,想象你想要定义一个只能存储任意 Number 实例的容器。
我们可以在定义 type members 加上这样的约束:
trait OnlyNumbersContainer {
type A <: Number
def value: A
}
或者我们可以稍后在类层次结构中添加约束,例如通过混入声明 "only Numbers" 的特质:
trait SimpleContainer {
type A
def value: A
}
trait OnlyNumbers {
type A <: Number
}
val ints = new SimpleContainer with OnlyNumbers {
type A = Integer
def value = 12
}
// 下面的定义不能通过编译
val _ = new SimpleContainer with OnlyNumbers {
def value = "" // error: type mismatch; found: String(""); required: this.A
}
正如你所看到的,我们可以像使用 Type Parameters 一样使用 Abstract Type Members, 但是我们无需忍受显式四处传递类型的痛苦 - 因为类型是个字段,我们需要传递。 我们需要付出的代价就是按名称绑定这些类型。
12. Self-Recursive Type
在多数文献中,Self-recursive Types 被称为 F-Bounded Types, 所以你会发现许多文章或者博客都提到 "F-bounded"。 实际上,F-bounded 是 "self-resurive" 的另一个称呼,表示子类型约束自身被出现在类型参数左侧的一个 binders 参数化情况。 由于 self-recursive 含义更直观,所以我们会本小节中继续使用(而小节标题旨在帮助那些试图 google 什么是 "F-bounded" 的人)
12.1. F-Bounded Type
虽然 self-resurive type 并不是 Scala 的特定类型,但是有时还是会引起一些注意。
对于许多人来说,一个熟悉(也有可能不知道)的 self-recursive type 例子是 Java 的 Enum<E>,如果你对此感兴趣,
可以查看 Enum 源码。
不过现在让我们回到 Scala ,首先看看我们实际上在讨论什么。
| 在本小节,我们不会深入讨论这一类型。 如果你对在 Scala 中深入使用 self-recursive type 感兴趣,可以看看 Kris Nuttycombe 的 F-Bounded Type Polymorphism Considered Tricky。 |
想象你有一个 Fruit 特质,Apple 和 Orange 类继承了这个特质。Fruit 特质还有一个 "compareTo" 方法,
现在问题来了:想象一下你想实现 "我不能用 oranges 与 apples 比较,因为它们是完全不同的东西!"。
首先让我们看看不考虑编译安全的最简单实现:
// 最简单的实现,Fruit 没有被自递归参数化
trait Fruit {
final def compareTo(other: Fruit): Boolean = true // 在我们的例子中实现不重要,我们只关心编译时
}
class Apple extends Fruit
class Orange extends Fruit
val apple = new Apple()
val orange = new Orange()
apple compareTo orange // 编译成功,但我们希望这句话不能通过编译
在上面朴素的实现中,因为 Fruit 特质不知道任何继承它的类的线索,所以不能限制 compareTo 的签名使得其只能接受"与 this 相同的子类(the same subclass as this)"的参数。
让我们使用 Self Recursive Type Parameter 重写这个例子:
trait Fruit[T <: Fruit[T]] {
final def compareTo(other: Fruit[T]): Boolean = true // 在我们的例子中实现并不重要
}
class Apple extends Fruit[Apple]
class Orange extends Fruit[Orange]
val apple = new Apple
val orange = new Orange
注意到 Fruit 签名中的类型参数。你可以读作"我接受一个类型参数 T,并且 T 必须是一个 Fruit[T]",
要满足这样要求的唯一方法是像类 Apple 和 Orange 那样继承这个特质。
现在,如果我们尝试将 apple 与 orange 比较,我们会得到一个编译错误:
scala> orange compareTo apple
:13: error: type mismatch;
found : Apple
required: Fruit[Orange]
orange compareTo apple
scala> orange compareTo orange
res1: Boolean = true 现在我们能确定我们只能将 apples 与 apples 比较,其他水果与同类型的 Fruit(子类)比较。
当然这里还有更多需要讨论的 - 我们能将 Apple 和 Orange 的子类分别与 Apple 和 Orange 比较吗?
因为在类型层次中实现 Apple 和 Orange 时,我们填入的类型参数分别是 Apple 和 Orange,
我们的意思是 Apple 只能与 Apple 比较,这也意味着 Apple 的子类可以互相比较 -
这依然满足 Fruit 签名的 compareTo 限制,因为现在我们的调用右边是比 Fruit[Apple] 更具体的类型。
比如,让我们尝试将一个日本 apple(ja. "りんご", "ringo")和一个波兰 apple(pl. "Jabłuszko")比较:
object `りんご` extends Apple
object Jabłuszko extends Apple
`りんご` compareTo Jabłuszko
// true
| 你可以使用更花哨的技巧实现同样的类型安全,比如 path dependent types 或者 implicit parameters 和 type classes。但是这里最简单的办法是使用 self-recursively type。 |
13. Type Constructor ✗
Type Constructor 的作用非常类似于函数,但是作用在类型级别。也就是说,在普通编程中,你可以有一个函数,接受一个值 a 并基于这个值返回另一个值 b;
那么在类级别编程(type-level programming)中,你可以将 List[+A] 看成一个有类似功能的 type constructor:
-
List[+A]接受一个类型参数(A), -
List[+A]本身不是一个合法的类型,你需要填入一个类型参数A- "构造这个类型(construct the type)", -
通过填入
Int,你会得到一个具体的类型List[Int]
基于上面的例子,你可以看到 type constructor 与普通的 constructors 非常相似 - 唯一的区别是我们在处理类型(type)而不是对象的实例(instances of objects)。
在这里值得一提的是,在 Scala 中我们不能说某个变量的类型是 List,不像在 Java 中存在原始类型 List<Object>。
Scala 更严格,不允许我们使用 just a List 代替一个具体类型,因为它期望一个真正的类型 - 而不是一个 type constructor。
在 Scala 2.11.x,与这个主题相关的是,我们在 REPL 中有了一个强大的命令 - :kind 命令。
该命令允许你检查一个类型是否是 higher kind。首先让我们来看看一个简单的 type constructor,比如 List[+A]:
// Welcome to Scala version 2.11.0-M5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0-ea).
// Type in expressions to have them evaluated.
:kind List
// scala.collection.immutable.List's kind is F[+A]
:kind -v List
// scala.collection.immutable.List's kind is F[+A]
// * -(+)-> *
// This is a type constructor: a 1st-order-kinded type.
在这里我们看到 scalac 能够告诉我们 List 事实上是一个 type constructor(如果使用 -verbose 选项,编译器能输出更多的信息)。
让我们来研究下这个语法: * -> *。这个语法被广泛用于表示 kinds,实际上我发现该语法可能受到了 Haskell 的启发 - 这是 Haskell 用来打印函数签名的语法。
这个语法最直观的读法是"接受一种类型,返回另一种类型"。你可能注意到我们省略了 Scala REPL 的输出,即关系中的加号(如 * -(+)-> *),这表示 variance bounds,
你可以在 Type Variance in Scala 一节了解更多。
如前所述,List[+A](或者 Option[+A],或者 Set[+A]… 或者接受一个类型参数的类型)是 type constructor 最简单的情况 -
它们只接受一个类型参数。我们称这样的 type constructor 为 first-order kinds(* -> *)。
值得一提的是,即使一个 Pair[+A, +B](可以表示成 * -> * -> *)也还是 first-order 而不是 higher-order kind。
在下一小节,我们将分析什么是 higher order kind 以及如何发现它们。
14. Higher-Order Kind ✗
| TODO 现在还没有有价值的东西,即将到来…. |
另一方面,Higher Kinds Higher Kinds 允许我们对 type constructors 抽象,正如 type constructors 允许我们对 type 抽象。
一个经典的例子就是 Monad:
scala> import scalaz._
import scalaz._
scala> :k Monad // Finds locally imported types.
Monad's kind is (* -> *) -> *
This is a type constructor that takes type constructor(s): a higher-kinded type.15. Case Class
Case Classes 是 Scala 中最有用的编译器技巧之一。
它们本身不是很复杂,能帮助实现非常乏味和无聊的 equals、hashCode 和 toString 等方法,
还可以配合模式匹配调用 apply/unapply 方法等等。
在 Scala 中可以像定义普通类一样定义一个 case class,但是需要加上 case 关键字:
case class Circle(radius: Double)
只需要这一行代码,我们就实现了 Value Object 模式。 定义了这样一个 case class 意味着我们自动得到了这些好处:
-
case class 的实例是不可变的(immutable)
-
可以使用
equals进行比较,并且相等性是基于字段的(而不是像普通类那样比较对象相等性) -
它的
hashcode遵循equals合同,也是基于这个类的字段 -
它的构造方法参数自动成为
public val而无需声明(例如上面例子中的radius) -
它的
toString是由类名和它所包含的字段的值组成的(对于我们的 Circle,toString 实现为def toString = s"Circle($radius)")。
是时候总结一下我们学到的,然后应用到"现实生活"的例子中, 这一次我们要实现一个 Point 类,因为我们需要多于一个字段才能展示 case class 为我们提供的一些有趣特性:
case class Point(x: Int, y: Int) (1)
val a = Point(0, 0) (2)
// a.toString == "Point(0,0)" (3)
val b = a.copy(y = 10) (4)
// b.toString == "Point(0,10)"
a == Point(0, 0) (5)| 1 | x 和 y 被自动地定义成 val 成员 |
| 2 | 同时会生成一个 Point 伴生对象,带有 apply(x: Int, y: Int) 方法,可以用来创建一个 Point 实例 |
| 3 | 自动生成的 toString 方法包含类名和参数值 |
| 4 | copy(...) 方法允许通过仅改变选择的字段轻松创建派生对象 |
| 5 | case class 的相等性是基于值的(equals 和 hashCode 是根据 case class 的参数生成的) |
不仅如此,case classes 还可以用于模式匹配,不论是"普通"还是"提取器(extractor)"语法(赋值给:)
Circle(2.5) match {
case Circle(r) => println("Radius = " + r)
}
val Circle(r) = Circle(4.0)
val r2 = r * r // r2 现在是 16.0
16. Enumeration
Scala 不像 Java 中有内置的 "enum"。但是我们可以使用一些(嵌入在 Enumeration 类)的小技巧,写出类似的枚举。
16.1. Enumeration
当前 Scala (2.10.x)实现类似枚举的结构是 Enumeration 类:
object Main extends App {
object WeekDay extends Enumeration { (1)
type WeekDay = Value (2)
val Mon, Tue, Wed, Thu, Fri, Sat, Sun = Value (3)
}
import WeekDay._ (4)
def isWorkingDay(d: WeekDay) = ! (d == Sat || d == Sun)
WeekDay.values filter isWorkingDay foreach println (5)
}| 1 | 首先我们声明一个可以包含我们枚举值的 object,继承 Enumeration |
| 2 | 这里我们为 Enumerations 内部 Value 类型定义一个 Type Alias,因为我们使用名字匹配 object 的名字,我们就可以通过 WeekDay 引用 Value(是的,这几乎就是个黑魔法) |
| 3 | 这里我们使用 "multi assignment",左边的每个 val 会被赋予不同 Value 的实例。你也可以写成 7 个 val |
| 4 | 这句 import 做了两件事:首先我们不需要加上前缀 WeekDay 就可以引用 Mon 了;另外 import 也将 type WeekDay 引入当前作用域,所以我们可以在下面的方法定义中直接使用。 |
| 5 | 最后,我们得到一些枚举方法。这些方法并不是魔术,因为大多数方法在我们创建新的 Value 实例就存在了。 |
正如你所看到的,枚举在 Scala 中并不是内置的,而是基于 Scala 类型系统巧妙地实现的,使它看起来像一个枚举类。 在某些情况下,这样的实现也许够用,但是还是没有 Java enum 丰富,比如添加新的值和行为。
16.2. @enum
@enum 注解当前还只是一个提议,正在 scala-internals 上讨论: enumeration must die.
|
与即将到来的注解宏一起,我们可能会有 @enum 注解,这在相关 Scala Improvement Process 文档中有所描述: [enum-sip].
@enum
class Day {
Monday { def goodDay = false }
Tuesday { def goodDay = false }
Wednesday { def goodDay = false }
Thursday { def goodDay = false }
Friday { def goodDay = true }
def goodDay: Boolean
}
17. Value Class
Value class 在 Scala 中已经存在很久了,而且你已经使用过很多次了,
这是因为 Scala 中所有数值(numeric value)都使用这个编译器技巧避免类似 scala.Int 到 java.lang.Integer 的装箱和拆箱等。
让我们回顾一下,Scala 的 Array[Int] 实际上是一个 JVM int[](或者对于熟悉字节码的人来说,int[] 是一个称为 [I] 的 JVM 运行类型)
我们知道,一个只包含数字的数组是非常快的,但是一个只包含引用的数组则相对较慢。
好了,现在我们知道编译器有一些花哨的技巧避免将 ints 装箱到 Integers 不必要的转换。
让我们看看从 Scala 2.10.x 开始该如何使用这样的功能。这样的功能被称为 "value classes",可以很容易的用到你现有的类中。你只需要给你的类加上 extends AnyVal,并且遵循下面列出的一些规则。
如果你对 AnyVal 不熟悉,可以查看 Unified Type System - Any, AnyRef, AnyVal 一节。
在我们的例子中,让我们来实现一个 Meter 作为普通 Double 的包装类并且能够将米(公制,meters)的数量转换成英尺(英制,Foot)的数量。
我们之所以需要这个类,因为没有人理解英制单位系统;-)。但缺陷是,如果有 95% 的时间我们都只是使用
一个普通 meter 值,为什么我们还需要为 scala.Double 包装类付出额外的运行时代价(每个实例需要额外的字节!)- 因为这是个面向欧洲市场的项目?
这时候我们需要 value class 来拯救!
case class Meter(value: Double) extends AnyVal {
def toFeet: Foot = Foot(value * 0.3048)
}
case class Foot(value: Double) extends AnyVal {
def toMeter: Meter = Meter(value / 0.3048)
}
在这所有的例子中,我们会使用 Case(Value) Class,虽然从技术上来说这并不需要(但是非常方便)。
你也可以使用一个带 val 参数的普通类实现 Value Class,但通常使用 case classes 是最好的方法。
你可能会问为什么只需要一个参数 - 这是因为我们在尝试避免包装值(wrapping the value),而这样的方法只适用于单个值,否则我们需要在某个地方维护一个 Tuple,但这得不偿失,我们很快会弄糊涂并且失去不包装的性能。
所以记住,value class 只适用于单个参数,但是参数不一定要是原始类型,也可以是普通的类,如 Fruit 或者 Person,我们还是可以在 Value Class 中避免包装这些值。
要定义一个 Value Class,你只需要定义一个只有一个公有 val 参数并且继承了 AnyVal 的类,并遵循它的一些限制。
这个参数不需要是原始类型,可以是任意类型。另一方面,这些限制(局限)是一个长列表,例如一个 Value Class 不能包含除 def 成员以外的任何字段,并且类本身不能被继承等。
有关 Value Class 完整限制和更深入的示例,请参考 Scala 文档 Value Classes - summary of limitations。
|
好了,现在我们得到了 Value Case Classes Meter 和 Foot,让我们检查下当我们加上了 extends AnyVal 部分,
将 Meter 从一个普通的 case class 变成一个 Value Class,生成的字节码是如何改变的。
// case class
scala> :javap Meter
public class Meter extends java.lang.Object implements scala.Product,scala.Serializable{
public double value();
public Foot toFeet();
// ...
}
scala> :javap Meter$
public class Meter$ extends scala.runtime.AbstractFunction1 implements scala.Serializable{
// ... (skipping not interesting in this use-case methods)
}
以及为 value class 生成的字节码:
// case value class
scala> :javap Meter
public final class Meter extends java.lang.Object implements scala.Product,scala.Serializable{
public double value();
public Foot toFeet();
// ...
}
scala> :javap Meter$
public class Meter$ extends scala.runtime.AbstractFunction1 implements scala.Serializable{
public final Foot toFeet$extension(double);
// ...
}
基本上这里只有一件事值得我们关注,编译器为 Value Class 生成的 Meter 伴生类有了一个新方法 - toFeet$extension(double): Foot。
在此之前,这个方法只是 Meter 类的实例方法,不接受任何参数(所以它实际上是 toFeet(): Foot)。生成的方法被标记为 "extension",
这实际上正是我们给这种方法的名称(.NET 开发者可能知道这是在做什么)。
我们使用 Value Classes 的目的是避免分配一个 value object,而是直接使用被包装的值,
那么我们必须停止使用实例方法 - 因为这些实例方法会创建一个包装类(Meter)等。
我们能做的是将这个实例方法提升为扩展方法(extension method),正如我们存储在 Meter 伴生对象中那些方法,
另外不直接使用实例的 value: Double 字段,而是每次调用扩展方法时传递一个 Double。
Extension methods 和 Implicit conversion 有同样的功能(Implicit conversion 更强大和通用),
但是某些方面比 conversions 要简单 - 它们避免了创建 "Wrapper" 对象,
而 implicit conversions 需要创建 wrapper 对象才能提供 "added methods" 的功能。
Extension methods 采取了重写生成方法的方式,所以它们接受需要被扩展的类型作为第一个参数。
举个例子,当你调用 3.toHexString,这个方法是通过 implicit conversion 加入到 Int 中,
但是 implicit conversion 的转换目标是 class RichInt extends AnyVal,
所以 RichInt 是一个 Value Class。那么这次调用不会创建一个 RichInt 对象,而是会被重写为 RichInt$.$MODULE$.toHexString$extension(3),这样就避免了创建 RichInt。
|
让我们使用我们新学到的知识来调查在 Meter 例子中编译器实际上会为我们做什么。
我们编写的代码时,会在源代码旁边注释解释编译器实际产生的字节码(即,当我们运行代码时会发生什么)
// 源代码 // 产生的字节码实际做了什么
val m: Meter = Meter(12.0) // 存储 12.0 (1)
val d: Double = m.value * 2 // 存储浮点数相乘(12.0 * 2.0) (2)
val f: Foot = m.toFeet // 调用 Meter$.$MODULE$.toFeet$extension(12.0) (3)| 1 | 可能有人会认为这里会创建一个 Meter 对象,但是因为我们在使用 Value Class,实际上只存储被包装的值 - 也就是说在运行时,我们实际上在使用 double(赋值和类型检查依然“验证”这好像是一个 Meter 实例) |
| 2 | 这里我们访问 Value Class 的 value(字段名字不重要)。注意到运行时虚拟机直接操作原始的 double,所以事实上并没有调用 value 方法,就好像我们在使用普通的 case class |
| 3 | 这里似乎我们将要调用定义在 Meter 上的实例方法,但实际上,编译器已经用一个扩展方法调用代替了这次调用,然后向扩展方法传递了 12.0。我们得到了一个 Foot 实例…等等,Foot 也是定义成 Value Class,所以运行时我们再次得到一个普通的 double。
我们不必关心关心源代码 - 使用 Value Class 我们能获得性能上的好处,还不影响代码的语义 |
这些就是 extension methods 和 value classes 的基础。如果你想了解更多关于 Value Class 的更多案例,请参考 official documentation’s section about Value Classes 其中 Mark Harrah 使用很多例子很好的解释了 Value Classes,所以在这里除了基本介绍我不会重复他的努力:-)。
18. Type Class ✗
Type Classes 属于 Scala 中最强大的模式,可以总结为(如果你喜欢花哨的措辞)"ad-hoc polimorphism"。当你读完这节,就应该可以理解这个词的含义了。
Type Classes 为我们解决的典型问题是不需要将两个类绑定在一起就可以提供可扩展的 API。
这样一个严格绑定,可以使用 Type Classes 避免的例子是继承 Writable 接口,使得我们自定义数据类型可写:
// 还没有 type classes
trait Writable[Out] {
def write: Out
}
case class Num(a: Int, b: Int) extends Writable[Json] {
def write = Json.toJson(this)
}
使用这种风格,继承并实现接口,我们将 Num 绑定到 Writable 接口,而且我们必须"此时此刻"就要提供 write 的实现,
这使得其他人很难提供不同的 write 实现 - 他们必须继承 Num!
另外一个痛点是,我们不能使用一个类两次继承同一个特质,提供不同的序列化目标(你不可以同时继承 Writable[Json] 和 Writable[Protobuf])。
所有的这些问题都可以使用基于 Type Class 而不是直接继承 Writeable[Out] 的方法解决。
让我们试试看,并详细解释这是如何工作的:
trait Writes[In, Out] { (1)
def write(in: In): Out
}
trait Writable[Self] { (2)
def write[Out]()(implicit writes: Writes[Self, Out]): Out =
writes write this
}
implicit val jsonNum = Writes[Num, Json] { (3)
def (n1: Num, n2: Num) = n1.a < n1.
}
case class Num(a: Int) extends Writable[Num]| 1 | 首先我们定义一个 Type Class,它的 API 与之前的 Writable 特质类似,但是我们不将它混入到一个需要被写入的类,而是将其分开,并且为了知道它的具体实现,我们使用 Self 类型参数 |
| 2 | 下一步我们将 Writable 特质使用 Self 参数化,然后序列化目标类型被移到 write 的签名。现在,write 还需要一个隐式 Writes[Self, Out] 实现处理序列化 - 这就是我们的 Type Class 的实例 |
| 3 | 这就是 Type Class 的实际实现,注意到我们将实例标记为 implicit,这样它就可用于 write()(implicit Writes[_, _]) 方法 |
20. Self Type Annotation
Self Types 可用于表达"依赖(require)"关系,如果其他类要使用这个特质,它应该提供这个特质所依赖的实现。
让我们看看一个例子,其中一个 service 需要一个 Module 提供的其他类型的 service。我们可以用下面的 Self Type 注解表达:
trait Module {
lazy val serviceInModule = new ServiceInModule
}
trait Service {
this: Module =>
def doTheThings() = serviceInModule.doTheThings()
}
第二行 this: Module => 可以被读作 "I’m a Module"。这看起来和定义一个继承 Module 的特质类似。
那么这与直接继承 Module 有什么区别吗?
当使用 self type 时,这意味其他人要使用 Service 必须在实例化时提供一个 Module 或者 Module 子类型实例:
trait TestingModule extends Module { /*...*/ }
new Service with TestingModule
如果你尝试实例化而不混入所需要的特质,那么就会像下面这样失败:
new Service {}
// class Service cannot be instantiated because it does not conform to its self-type Service with Module
// new Service {}
// ^
你还应该记住,使用 self-type 语法时可以指定一个以上的特质。现在让我们来谈谈为什么它叫做 self-type(除了可耻地点头"是的,这样的命名很合理“)。 这是因为一种使用 self-type 的流行方式如下:
class Service {
self: MongoModule with APIModule =>
def delegated = self.doTheThings()
}
事实上,你可以使用任何合法标识符(不仅仅是 this 或者 self)然后在你的类中引用它。
21. Phantom Type
Phantom Types 听起来很奇怪,但它的作用很契合它的名字,可以解释为“永远不能实例化的类型”。 通常我们不会直接使用它们,而是用它们在我们的类型中执行更严格的逻辑。
在这个例子中,我们会使用一个 Service 类,包含 start 和 stop 方法。
现在我们想确保你不能(类型系统不允许你)启动一个已经启动的 service,反之亦然。
让我们开始准备我们的"标记特质",它们不包含任何逻辑 - 我们仅仅使用它们来表达 service 的状态:
sealed trait ServiceState
final class Started extends ServiceState
final class Stopped extends ServiceState
注意我们将 ServiceState 标记为 sealed 确保其他人不能向我们的系统再添加新的状态。
我们也将 Started 和 Stopped 定义为 final,这样其他人不能继承它们,然后向系统添加新的类型。
|
|
定义好之后,我们就可以将它们作为 Phantom Types 使用。
首先让我们定义一个 Service 类,接受一个 State 类型参数 - 注意在这个类中我们没有用到任何 State 类型的值。
它仅仅存在那里,像一个鬼魂,或者幽灵 - 这就是它名字的来源:
class Service[State <: ServiceState] private () {
def start[T >: State <: Stopped]() = this.asInstanceOf[Service[Started]]
def stop[T >: State <: Started]() = this.asInstanceOf[Service[Stopped]]
}
object Service {
def create() = new Service[Stopped]
}
然后在伴生对象中,我们定义了 Service 的一个实例,一开始它的状态是 Stopped。Stopped 状态符合类型参数的类型限制(<: ServiceState)。
当我们想要启动/停止一个已经存在的 Service,有趣的事情发生了。例如,start 方法的类型限制只对 T 的一个值 Stopped 有效。
在我们的例子中,为了转换到相反的状态,我们返回同样的实例,并且显式转换到需要的状态。
因为没有其他类型使用这个类型,在转换过程你不会遇到 class cast 异常。
现在让我们使用 REPL 来研究上面的例子,这将作为本节一个很好的补充:
scala> val initiallyStopped = Service.create() (1)
initiallyStopped: Service[Stopped] = Service@337688d3
scala> val started = initiallyStopped.start() (2)
started: Service[Started] = Service@337688d3
scala> val stopped = started.stop() (3)
stopped: Service[Stopped] = Service@337688d3
scala> stopped.stop() (4)
<console>:16: error: inferred type arguments [Stopped] do not conform to method stop's
type parameter bounds [T >: Stopped <: Started]
stopped.stop()
^
scala> started.start() (5)
<console>:15: error: inferred type arguments [Started] do not conform to method start's
type parameter bounds [T >: Started <: Stopped]
started.start()| 1 | 这里我们创建了一个初始实例,初始状态为 Stopped |
| 2 | 可以启动一个状态为 Stopped 的 service,返回类型是 Service[Started] |
| 3 | 可以停止一个状态为 Started 的 service,返回类型是 Service[Stopped] |
| 4 | 然而停止一个已经停止的 service(Service[Stopped])是非法的,不能通过编译。注意打印出的类型限制! |
| 5 | 类似地,启动一个已经启动的 service(Service[Started])也是非法的。注意打印出的类型限制! |
正如你所看到的,Phantom Types 是另一种使得我们代码更加类型安全的方式(或者我应该说 "状态安全"!?)
| 如果你好奇哪个”不那么疯狂的库“使用了 Phantom Type, 一个很好的例子是 Foursquare Rogue(MongoDB 查询 DSL), 使用了 Phantom Type 确保一个 query builder 在正确的状态 - 比如可以在 builder 上正确调用 limit(3)。 |
22. Structural Type
如果你想有一个直观的理解,Structural Type 通常被描述为"类型安全的鸭子类型(type-safe duck typing)",
到现在为止,我们都是从“它是否实现了接口 X"的方式思考类型。有了 structural types,我们可以更进一步,开始推理一个给定对象的结构(这就是它名字的来源)。 当使用 structure typing 检查一个类型时,我们需要问"这个类型是否有符合这个签名的方法"。
让我们看看一个非常流行的例子,理解为什么 structural type 很强大。
想象一下,你有许多可以被关闭(closed)的类。在 Java 的世界中,人们通常会实现 java.io.Closeable 接口,以便编写一个常用的 Closeable 工具类(事实上,Google Guava 便提供了这样的工具类)。
现在想象有其他人实现了一个 MyOwnCloseable 类但是没有继承 java.io.Closeable。
由于静态类型限制,你的 Closeables 库就不能使用这个类了,你不能将一个 MyOwnCloseable 实例传递给你的库。
让我们使用 Structural Typing 来解决这个问题:
type JavaCloseable = java.io.Closeable
// 注意,JavaCloseable 实际上是: { def close(): Unit }
class MyOwnCloseable {
def close(): Unit = ()
}
// 接受一个 Structural Type 的方法
def closeQuietly(closeable: { def close(): Unit }) =
try {
closeable.close()
} catch {
case ex: Exception => // 忽略...
}
// 接受一个 java.io.File 实例(实现了 Closeable):
closeQuietly(new StringReader("example"))
// 接受一个 MyOwnCloseable 实例
closeQuietly(new MyOwnCloseable)
structural type 被定义为 closeQuietly 的参数。这基本在说我们希望这个类型应该包含 close 方法。 它还可以有其他方法 - 所以 structural types 不是一个精确的匹配,而是定义了一个合法类型至少要包含方法的最小集合。
使用 Structural Typing 要牢记的另一个事实是它有非常巨大的(负面的)运行时性能影响,因为它是使用反射实现的。 在这个例子中我们不会去查看对应的字节码,但是要记住,在 Scala REPL 中使用 :javap 可以非常容易地查看 scala(或者 java)类生成的字节码。 所以你应该自己去尝试下。
在我们讨论下一个话题前,让我简要介绍一个小巧但是整洁的技巧。 想象一下,你的 Structural Type 非常大,一个例子是表示一个可以打开,使用,然后关闭的类型。 通过在 Structural Type 中使用 Type Alias,我们可以将类型定义与方法定义分开,正如下面这种情况:
type OpenerCloser = {
def open(): Unit
def close(): Unit
}
def on(it: OpenerCloser)(fun: OpenerCloser => Unit) = {
it.open()
fun(it)
it.close()
}
通过使用 type alias,我们使得 def 定义更加清晰了。
我强烈建议对较大的 Structural Type 使用 Type Alias。
最后提醒,考虑到 structural type 的负面性能影响,你总是要检查你是否真的需要 structural typing,而不能使用其他方式实现。
23. Path Dependent Type
Path dependent type 允许我们对一个类的内部类做类型检查。 这一开始看起来很奇怪,但只要你看到这个类型的例子,你就会发现很直观:
class Outer {
class Inner
}
val out1 = new Outer
val out1in = new out1.Inner // 具体实例, 从 Outer 的内部创建
val out2 = new Outer
val out2in = new out2.Inner // 另一个 Inner 实例, 外层实例是 out2
// 定义 path dependent type。其中 "path" 就是"inside out1".
type PathDep1 = out1.Inner
// 类型检查
val typeChecksOk: PathDep1 = out1in
// OK
val typeCheckFails: PathDep1 = out2in
// <console>:27: error: type mismatch;
// found : out2.Inner
// required: PathDep1
// (which expands to) out1.Inner
// val typeCheckFails: PathDep1 = out2in
这里要理解的关键是"每个外部类都有自己的内部类",所以每个内部类都是不同的类型 - 依赖于我们使用哪条路径到达内部类。
这种类型是非常有用的,我们可以强制从一个具体参数中得到类型。一个使用这种类型的例子如下:
class Parent {
class Child
}
class ChildrenContainer(p: Parent) {
type ChildOfThisParent = p.Child
def add(c: ChildOfThisParent) = ???
}
现在我们在类型系统使用 path dependent type 编码了这个逻辑,即这个容器只能包含 p 这个父类的孩子 - 而不是"任何父类"。
很快我们会在 Type Projections 一节看到如何表达 "child of any parent"。
24. Type Projection
Type Projections 允许你引用一个内部类的类型,从这方面看,它类似于 Path Dependent Types。 从语法来看,你可以使用 # 符号分离出内部类的路径。首先,让我们看看 Type Projections 的例子以及它们("#" 语法)与 path dependent types("." 语法)的区别:
// 我们的示例类结构
class Outer {
class Inner
}
// 使用 Type Projection (和 alias) 引用 Inner
type OuterInnerProjection = Outer#Inner
val out1 = new Outer
val out1in = new out1.Inner
关于 path dependent 和 projections 另一个很直观的印象是 Type Projections 可以用于 "type-level programming";-)
回到 Path Dependent Type 的例子,如果想要表达 "child of any parent",可以这么写:
class Parent {
class Child
}
class ChildrenContainer {
type ChildOfAnyParent = Parent#Child
def add(c: ChildOfAnyParent) = ???
}
25. Existential Types
Existential Types 与类型擦除密切相关,而所有 JVM 语言都必须面对类型擦除。
val thingy: Any = ???
thingy match {
case l: List[a] =>
// 小写字母 'a', 匹配所有类型... '那么 'a' 的类型是什么呢?!
}
因为运行时类型擦除,我们不知道 a 的类型。
我们只知道 List 是一个 type constructor,* -> *,所以一定存在某些类型 T 可以被 List 用来构造出一个合法的 List[T]。
这里的某些类型,就是 existential type!
Scala 为此提供了一个缩写:
List[_]
// 表示一个未知类型,但是不知道是哪一个
假设你正在使用 Abstract Type Member,在我们的例子就是一些 Monad。
我们想要用户在 Monad 中只能使用 Cool 实例,因为比如说,这样我们的 Monad 类型才有意义。
我们可以使用 Existential Type T 做类型限制实现:
type Monad[T] forSome { type T >: Cool }
26. Specialized Types
26.1. @specialized
比起"类型系统",Type specialization 实际上更像是性能技巧,
但是如果你想要写出性能良好的集合那么它是非常重要的,值得用心牢记。
在我们的例子中,我们将实现一个非常有用的集合,叫做 Parcel[A],能够保存一个指定类型的值 - 这是多么有用!
case class Parcel[A](value: A)
这就是我们的基本实现。那么缺点在哪里呢?因为 A 可以是任何类型,即使我们只放入一个 Int
,它也是被表示为 Java object。所以上面的类只能处理 objects,对于原始类型需要装箱和拆箱。
val i: Int = Int.unbox(Parcel.apply(Int.box(1)))
正如我们所知道 - 不必要的装箱并不是一个好主意,因为它在运行时需要更多的工作量,来回转换 int 和 object Int。
有什么可以解决这个问题呢?在这里能应用的一个技巧是为所有的原始类型 "specialize 我们的 Parcel 类(比如现在只需要 Long 和 Int),正如这样:
如果你已经读过 Value Class 一节,你可能会注意到 Parcel 可以轻松使用它们来实现。
这的确是事实。不过,Scala 从 2.8.1 就引入了 specialized,而在 2.10.x 才引入 Value Classes。
而且,你可以专门化一个以上的值(尽管这会指数级地增加产生的字节码),而使用 Value Classes 你就被限制只能使用单个值。
|
case class Parcel[A](value: A) {
def something: A = ???
}
// "手动" specialzation
case class IntParcel(intValue: Int) {
override def something: Int = /* 基于底层 Int,没有包装! */ ???
}
case class LongParcel(intValue: Long) {
override def something: Long = /* 基于底层 Long,没有包装! */ ???
}
IntParcel 和 LongParcel 的实现能有效的避免装箱,因为他们直接使用原始类型,而没有触及到对象帝国。
现在取决于我们的使用,我们必须手动选择使用哪个 Parcel。
这样的实现很不错但是…如果有 N 个实现,包含每个我们想支持的原始类型(可以是 int,long,byte,char,short,float,double,boolean,void 加上 Object 的任意类型),那么我们需要维护很多样板代码。
既然我们熟悉了 specialization 的概念,我们不需要手动实现,来看看 Scala 是如何通过引入 @specialized 注解帮助我们的:
case class Parcel[@specialized A](value: A)
因为我们给类型参数 A 加上了 @specialized 注解,
这告诉编译器要为这个类生成所有 specialized 变体 - 即 ByteParcel,
IntParcel,LongParcel,FloatParcel,DoubleParcel,
BooleanParcel,CharParcel,甚至 VoidParcel(这些并不是实际实现的名字,但是你应该明白背后的想法)。
编译器还负责选择"正确"的类型,尽可能使用 specialized 版本(如果有的话),所以我们写代码时可以不关心这个类是否是 specialized:
val pi = Parcel(1) // 会使用 `int` specialized 方法
val pl = Parcel(1L) // 会使用 `long` specialized 方法
val pb = Parcel(false) // 会使用 `boolean` specialized 方法
val po = Parcel("pi") // 会使用 `Object` 方法
"太棒了,我们可以在任意的地方使用!" — 这是人们发现 specialiation 的常见反应,因为它可以数倍加快低级别操作速度,同时降低内存使用率。 不幸的是,我们需要很高的代价:如果对多个参数使用该注解,那么生成的代码就会变得非常庞大:
class Thing[A, B](@specialized a: A, @specialized b: B)
在上面的例子中,我们使用了 specialization 的第二种应用方式 - 将注解加在参数前 - 效果等价于我们直接 specialize A 和 B。
请注意到上面的代码会产生 8 * 8 = 64 种实现,这是因为编译器要处理 "A 是一个 int,B 是一个 int" 以及 "A 是一个 boolean,但是 B 是一个 long" 这些情况 - 你应该明白编译器做了什么。
事实上,最终生成的类的数量大约在 2 * 10^(nr_of_type_specializations),对于三个类型参数,很容易就产生了上千个类。
当然有办法限制这种指数增长,比如限制需要 specialization 的目标类型。 比如说我们的 Parcel 多数情况都用于整数类型,从不用于浮点数 - 我们可以告诉编译器只为我们生成 Long 和 Int 类型的:
case class Parcel[@specialized(Int, Long) A](value: A)
让我们使用 :javap Parcel 看看生成的字节码:
// Parcel, 为 Int 和 Long 专门化
public class Parcel extends java.lang.Object implements scala.Product,scala.Serializable{
public java.lang.Object value(); // 泛型版本, "处理其他所有情况"
public int value$mcI$sp(); // int specialized 版本
public long value$mcJ$sp();} // long specialized 版本
public boolean specInstance$(); // 检查我们是否在使用 specialized 类的实现
}
正如你所看到的,编译器为我们准备了额外的 specialized 方法,
比如 value$mcI$sp() 返回一个 int,value$mcJ$sp() 返回一个 long。
另一个值得提起的方法是 specInstance$,如果使用的是 specialized 类,那么该方法返回 true。
如果你好奇的话,当前这些类在 Scala 中会被 specialized(这个列表可能不完整):Function0,Function1,Function2,Tuple1,Tuple2,Product1,Product2,AbstractFunction0,AbstractFunction1,AbstractFunction2。 尽管可以 specialized 两个以上的参数,但是由于开销太大,人们通常不这么做。
我们要避免装箱的一个主要原因还包含内存效率。想象一个 boolean,
如果能在内存中使用一个 bit 存储它该多好呀。
悲伤的是这并不是事实(我所知道的任何 JVM),比如说在 HotSpot 中,一个 boolean 是用 int 表示的,那么它需要占据 4 个字节的空间。
另一个方面,它的表兄弟 java.lang.Boolean 需要 8 个字节存储对象头,正如每个 Java 对象都需要,在内部存储 boolean(需要额外 4 字节),
然后由于 Java 对象布局对齐规则(Object Layout Alignment Rules),这个对象所占据的空间会被对齐到 16 个字节(8 个字节存储对象头,4 个字节存储值,4 个字节对齐)。
这就是为什么我们非常想避免装箱的另一个原因。
|
26.2. Miniboxing ✗
| Miniboxing 不是 Scala 的一个特征,但是可以作为编译器插件与 scalac 一起使用。 |
我们在前一节解释到 specialization 是非常强大的,但同时也是"编译器炸弹",存在指数增长的可能性。
现在已经有一个解决办法了,那就是 Mibiboxing。Miniboxing 是一个编译器插件,能够实现与 @specialized 相同的功能,但不会生成上千个类。
| TODO EPFL 有一个项目可以使得 specialiation 更高效 Scala Miniboxing |
27. Type Lambda ✗
在 type lambda 中我们会用到 Path Dependent 和 Structural Types,所以如果你跳过了这些章节,你可能需要回去回顾下。
了解 Type Lambdas 之前,让我们回头看看函数和柯里化。
class EitherMonad[A] extends Monad[({type λ[α] = Either[A, α]})#λ] {
def point[B](b: B): Either[A, B]
def bind[B, C](m: Either[A, B])(f: B => Either[A, C]): Either[A, C]
}
28. Union Type ✗
| 这部分还不完整,请参考 Miles' 博客了解详细细节(下面有链接):-) |
在我们开始讨论这个类型之前需要回忆起集合论,然后从"交集类型"看待已经熟悉的构造 A with B:
为什么呢?这是因为唯一满足这样的类型限制的是那些有 type A 和 type B 的类型,那么在集合论中,这就是个交集。
另一方面,让我们思考什么是 Union Type。
Union Type 应该是两个集合的联合(union),使用集合表示应该是 type A 或 type B。
我们的任务是使用 Scala 的类型系统介绍这样的类型。虽然 Union Type 并不是 Scala 的 first-class 构件(它不是内置),我们可以很容易的实现它们。
如果你想要深入了解 Union Type,Miles Sabin 在 the blog post Unboxed union types in Scala via the Curry-Howard isomorphism 中详细解释了这个技巧。
type |∨|[T, U] = { type λ[X] = ¬¬[X] <:< (T ∨ U) }
def size[T : (Int |∨| String)#λ](t : T) = t match {
case i : Int => i
case s : String => s.length
}
29. Delayed Init
因为我们开始讨论 Scala 中"奇怪"的类型,那么我们需要为延迟初始(Delayed Init)开一节。
DelayedInit 实际上是一个"编译器技巧",对于类型系统没有太大影响,但是一旦你理解了它,
你就知道了 scala.App 是如何工作的,所以让我们深入到 App 的例子中:
object Main extends App {
println("Hello world!")
}
通过阅读上面的代码,基于我们基本的 Scala 知识,我们可能会认为"好了, 现在 println 实际上是 Main 的构造方法!"。
通常情况下这是没错的,但这次不是,这是因为 App 特质继承了 DelayedInit 特质
trait App extends DelayedInit {
// code here ...
}
让我们看看特质 DelayedInit 的完整版源代码:
trait DelayedInit {
def delayedInit(x: => Unit): Unit
}
正如你看到的,DelayedInit 不包含任何实现 - 与它相关的所有工作都由编译器完成,编译器会将所有继承 DelayedInit 的类和对象特殊处理(注意,特质不会像这样被重写)。这样特殊的处理方式如下:
-
想象你的类/对象身体是一个函数,所有的事情都是在这些类/对象体内完成
-
编译器会为你创建这个函数,然后传递给
delayedInit(x: => Unit)方法(注意参数是 call-by-name)。
让我们快速给一个例子,然后我们将手动实现 App 为我们做的工作(在 delayedInit 的帮助下)
// 我们写:
object Main extends DelayedInit {
println("hello!")
}
// 编译器产生:
object Main extends DelayedInit {
def delayedInit(x: => Unit = { println("Hello!") }) = // 需要我们自己填充实现
}
使用这样的机制你可以在任意时候运行类的 body。现在我们知道了 delayedInit 是如何工作的,让我们实现我们自己的 scala.App(使用与 scala.App 同样的机制)
trait SimpleApp extends DelayedInit {
private val initCode = new ListBuffer[() => Unit]
override def delayedInit(body: => Unit) {
initCode += (() => body)
}
def main(args: Array[String]) = {
println("Whoa, I'm a SimpleApp!")
for (proc <- initCode) proc()
println("So long and thanks for all the fish!")
}
}
// 运行下面的类会打印出:
object Test extends SimpleApp { //
// Whoa, I'm a SimpleApp!
println(" Hello World!") // Hello World!
// So long and thanks for all the fish!
}
这就是 DelayedInit 的工作方式。因为特质不会被重写,我们继承 DealyedInit 的 SimpleApp 不会被修改,多亏了这点,我们可以利用 delayedInit 方法,积累我们遇见过的 "class bodies"
(可以想象成我们正在处理一个深层次的类,然后 delayedInit 会被多次调用),最后像 Java 那样实现 main 方法依次调用 "class bodies"。
30. Dynamic Type
我曾经犹豫是否应该将 Dynamic Type 加入到这篇文章。最后,我决定还是加吧,因为这样的话可以使得这篇描述类型的文章更完整。那么问题是,为什么我会这么犹豫呢?
Scala 允许我们在一个 Staticly/Strictly Typed 语言中有 Dynamic Types!这就是为什么我考虑跳过,并想在其它位置描述它 - 因为它基本是在 "hacking around" 你所看过的类型。 让我们在看看实际例子,以及它是如何融入到 Scala 类型生态系统中的。
想象一个包含任意 JSON 数据 JsonObject 类。现在我们定义方法匹配这个 JSON 对象的键值,返回一个 Option[JValue],其中一个 JValue 可以是另一个 JObject,JArray,JString 或者 JNumber。
用法类似于下面的例子。
但是在这之前,要记得在文件(或者 REPL)导入开启这个语言特征。有不少特征(比如实验性质的宏)需要在文件中显式导入才能开启。 如果你想要了解更多有关这些特征,可以看看 scala.language 对象或者读一读文档 Scala Improvement Process 18 SIP-18
// 记住,我们需要导入才能开启这个语言特征
import scala.language.dynamics
// TODO: 缺少实现
class Json(s: String) extends Dynamic {
???
}
val jsonString = """
{
"name": "Konrad",
"favLangs": ["Scala", "Go", "SML"]
}
"""
val json = new Json(jsonString)
val name: Option[String] = json.name
// (一旦我们加入了实现)上述代码就可以通过编译
那么… 我们是如何在静态语言中融入动态类型的呢?答案很简单 - 编译器重写和一个特殊的标记特质:scala.Dynamic。
好了,结束胡言乱语然后回到基础。那么…我们怎么使用这些动态类型呢?事实上,我们需要实现几个魔术方法:
-
applyDynamic
-
applyDynamicNamed
-
selectDynamic
-
updateDynamic
让我们依次通过例子了解它们。
30.1. applyDynamic
好了,我们的第一个魔术方法看起来像:
// applyDynamic 例子
object OhMy extends Dynamic {
def applyDynamic(methodName: String)(args: Any*) {
println(s"""| methodName: $methodName,
|args: ${args.mkString(",")}""".stripMargin)
}
}
OhMy.dynamicMethod("with", "some", 1337)
applyDynamic 的签名接受方法名字和方法参数。在这里我们依次访问它们,构造出一个字符串。我们的实现仅打印出我们所关心的方法调用。 比如该方法是否真的得到了我们希望的参数值/方法名字?方法输出将会是:
methodName: dynamicMethod,
args: with,some,1337
30.2. applyDynamicNamed
好了,刚才的例子很简单。但是 applyDynamic 不能让我们控制参数的名字。如果我们能过写 JSON.node(nickname = "ktoso") 该多好呀?Hmm…事实是我们确实可以!
// applyDynamicNamed 例子
object JSON extends Dynamic {
def applyDynamicNamed(name: String)(args: (String, Any)*) {
println(s"""Creating a $name, for:\n "${args.head._1}": "${args.head._2}" """)
}
}
JSON.node(nickname = "ktoso")
这一次我们不仅得到一串参数值的列表,还得到了参数的名字。多亏了这个,这次例子的输出是:
Creating a node, for:
"nickname": "ktoso"
现在我可以想象基于 applyDynamicNamed 可以构建出一些很漂亮的 DSLs!
30.3. selectDynamic
现在,是时候看看一些更加"不寻常"的方法了。我们很容易理解 apply 方法。它们只是些拥有任意名字的方法。但是,是不是 Scala 中所有动态类型都需要定义成方法 - 或者说我们可不可以在对象中定义一个类似于字段的方法? 让我们尝试一下!这里的例子使用 applyDynamic,然后尝试表现出我们定义了一个没有 () 的方法:
OhMy.name // 编译错误
为什么用 applyDynamic 不行呢?我猜你已经知道原因了。这些方法(没有 ())会被特殊处理,因为它们通常代表字段。这样的调用不会触发 applyDynamic。
让我们看看我们的第一个 selectDynamic 调用:
class Json(s: String) extends Dynamic {
def selectDynamic(name: String): Option[String] =
parse(s).get(name)
}
这次,当我们执行 HasStuff.bananas,我们会得到 "I have bananas!"。注意到我们返回了值而不是将它打印出来。这是因为这次方法调用要表现的像一个字段一样。
而且这里描述的其他方法中也可以返回值(可以是任意类型)(applyDynamic 可以返回出一个字符串而不是打印出来)
30.4. updateDynamic
你会问还剩下什么呢?那么你可以问问你自己:既然我可以像 Dynamic 对象一样为某些字段定义了某些值…那么我还能用它来做什么呢?
我的回答是:"设置字段的值"。这就是 updateDynamic 的作用。但是 updateDynamic 有一条特殊的规则 - 只有你实现了 selectDynamic,它才有用。
如果我们只实现了 updateDynamic,我们会得到 selectDynamic 没有实现的错误,无法通过编译。
如果你仔细思考,你会发现从语义来说这很合理。
当我们完成了这个例子后,实际上我们可以让上一个(错误)代码片段正确工作。
object MagicBox extends Dynamic {
private var box = mutable.Map[String, Any]()
def updateDynamic(name: String)(value: Any) { box(name) = value }
def selectDynamic(name: String) = box(name)
}
使用这个 Dynamic "MagicBox",我们可以将值存放在任意的"字段"(它们看起来确实很像字段,但实际上并不是;-))。一个运行例子如下:
scala> MagicBox.banana = "banana"
MagicBox.banana: Any = banana
scala> MagicBox.banana
res7: Any = banana
scala> MagicBox.unknown
java.util.NoSuchElementException: key not found: unknown
另外…你是否感兴趣 Dynamic(https://github.com/scala/scala/blob/2.13.x/src/library/scala/Dynamic.scala[源代码见此])是如何实现的?有趣的是 Dynamic 特质本身没有做任何事情 - 它是"空的",仅仅是个标记接口。
显然,这里所有重活(调用方重写(call-site-rewriting))都由编译器完成。
31. Bibliography and Kudos
31.1. Reference and further reading
当然这篇文章要求相当多的研究和仔细检查,这里是所有我发现有用的链接(你可能也会):
-
[scala-spec] The Scala Language Specification
-
[enumeration-docs] http://www.scala-lang.org/api/current/index.html#scala.Enumeration
-
[enum-sip] https://docs.google.com/document/d/1mIKml4sJzezL_-iDJMmcAKmavHb9axjYJos_7UMlWJ8/edit
-
[twitter-scala-school] Twitter 的 Scala School: http://twitter.github.io/scala_school 包含了许多 Scala 概念,帮助我很好的解释了 Variance(是我发现过最好的解释)。
-
[universal-types] 非常老,但还是 Universal Types 的有效解释: http://www.scala-lang.org/old/node/128
-
[maciver-existentials] D.R. MacIver 的 Existential Types: http://www.drmaciver.com/2008/03/existential-types-in-scala/
-
[scala-doc] Scala API 文档: http://www.scala-lang.org/api/current/index.html
-
[dragos-specialized] Dragos 的演讲,非常好的介绍了 Scala 2.8 的
@specialized: Scala Days 2010 - Specialization -
[wiki-diamond] Wikipedia 上的菱形问题
-
[generics-specialization] Martin Odersky' 和 Iulian Dragos' 关于 specialization 的白皮书 Compiling generics through user-directed type specialization
-
[dangers-of-subtype-polymorphism] The dangers of correlating subtype polymorphism with generic polymorphism
-
[safar-linearization] Safari 上关于 Type Linearization 的在线书籍: http://blog.safaribooksonline.com/2013/05/30/traits-how-scala-tames-multiple-inheritance/
-
[phantom-types-haskell] James Iry 和他的 Phantom Types in Haskell and Scala 博客
-
[typesafe-builder] Scala 社区中有关 Phantom Types 的最早一篇博客(我认为),作者是 Rafael Ferreira Type Safe Builder Pattern in Scala
-
[kriss-type-lambda] StackOverflow 上关于 Type Lambdas 很棒的答案,作者是 Kriss Nuttycombe: http://stackoverflow.com/questions/8736164/what-are-type-lambdas-in-scala-and-what-are-their-benefits
-
[rogue-phantom-types] Jason Liszka 在 Foursquare 的博客中介绍了他们的 Rogue 库使用 Phantom Types Going Rogue part 2 - phantom types
-
[kind-pull-req] Adriaan Moors 向
scala提交的 :kind pull request https://github.com/scala/scala/pull/2340 -
[patronus-type] Eugene Yakota 的 constraining class linearization in scala,在这篇博客中他介绍他发现的 "patronus type" 模式
-
[the-flying-sandwich-part] Eugene Yakota 的 Scala 模式和开发建议 Scala: The flying sandwich parts
-
[package-object] Martin Odersky, Lex Spoon - Package Objects 网站(2010)
-
[union-types-miles] Miles Sabin 解释了 Union Types Miles Sabin on Union Types
-
[vampire-type] Vampire Methods for Structural Types
演讲
-
[types-of-types-lambda-days] Konrad Malawski(作者本人)在 Lambda Days Krakรณw 2014 对本文做了一个快速介绍和总览。这里有 视频 和 幻灯片
31.2. Thanks and kudos
我要特别感谢所有参与校对和审阅的人,你们帮助我打磨了这篇文章并且多次给了很有价值的反馈(按时间顺序:-)):
-
感谢 Sergio Rodrigez,他的文章审阅是我这辈子见过最有深度和建议的
-
感谢 Joshua Sureth 在 devoxx 午饭后的精彩评论和例子
-
感谢 SoftwareMill 的审阅和评论
-
感谢 VirtusLab 提出的拼写纠正、makefile 和建议
-
感谢 Kraków Scala User Group 的阅读校对和建议
-
所有提交了 PR 改进拼写和其他小错误的人
-
TODO, 还有更多的人
-
特别是你,感谢阅读
非常欢迎 PR 和评论,这个是 原文的git仓库,这个是 我本人翻译的 git 仓库。
我们的类型系统就介绍到这里了,如果你觉得有不完整或者需要改进的,可以给我或者给原作者发邮件。生活就是在学习 — Konrad ktoso Malawski
我的邮箱 wqlin